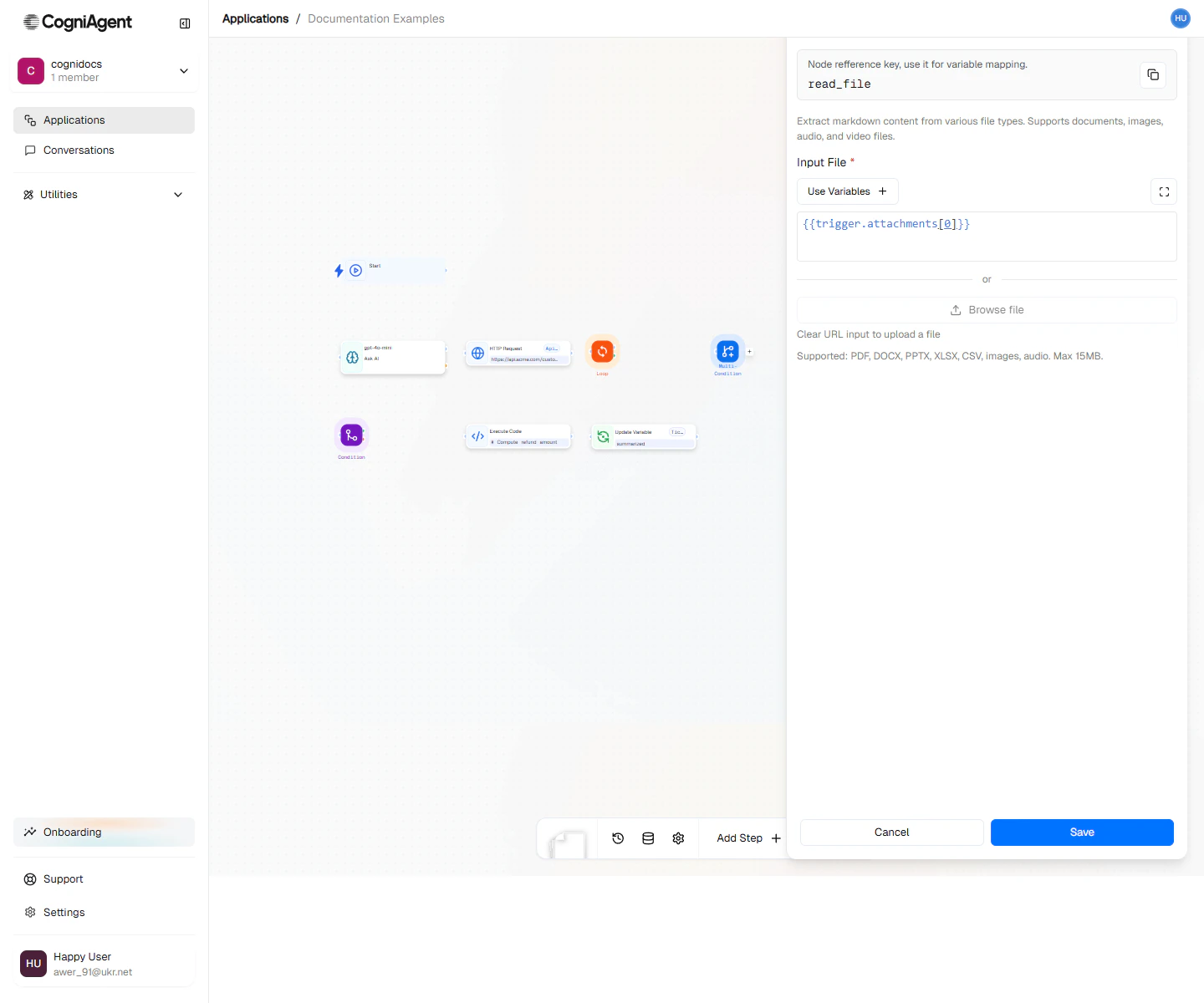
Read File configuration — point at a file URL or a variable from a previous node, then pick the output variable for the extracted text.
When to Use
- Reading documents - Get the text from PDFs, Word docs, PowerPoints
- Processing attachments - Read files that came with emails
- Reading text from images - Extract words from photos, scans, screenshots
- Importing data - Read CSV or Excel files
- Processing forms - Get the filled-in data from PDF forms
Supported File Types
Documents
Spreadsheets
Images
Example: Email Attachment Processor
Extract and analyze content from email attachments:1
Receive email with attachment
Use Event from App (Gmail) to trigger on emails with attachments.
2
Parse each attachment
Add a Loop node to iterate over
{{event_from_app_1.email.attachments}}:3
Analyze content
Use Ask AI node to analyze or summarize:
4
Store results
Add to a spreadsheet or send via Slack.
Example: Invoice Data Extraction
Extract structured data from PDF invoices:Example: Resume Scanner
Process job applications:Working with Multi-Page Documents
Process All Pages Together
Process Pages Individually
Extract Specific Pages
Configuration:pages: "1,5-10"
Only extracts pages 1 and 5 through 10.
Handling Tables
For documents with tables, use structured extraction mode:Reading Text from Images and Scans
If your file is an image or a scanned document, use OCR mode to read the text: Set extraction mode to: ocrOCR takes longer (usually 2-5 seconds per page) and isn’t always perfect. Double-check important extractions.
- Use higher quality images
- Make sure the text is clear and readable
- Note that handwriting usually doesn’t work well
When Things Go Wrong
File reading can fail because:- The file is damaged
- The file type isn’t supported
- The file is password-protected
- The file is too big
File Size Limits
For larger files, consider splitting or pre-processing.
Tips
Settings
string
default:"Read File"
What to call this node (shown on the canvas).
string
default:"parse_file_1"
A short code to reference this node’s content.
string
required
Where the file is coming from:
- url - Download it from a web address
- base64 - The file content encoded as text
- previous_node - A file from an earlier step (like an email attachment)
string
The web address to download from (if using URL source).
string
The encoded file content (if using base64 source).
string
Reference to a file from an earlier node (if using previous_node source).
string
default:"text"
How to read the file:
- text - Just get the words
- structured - Try to keep tables and lists intact
- ocr - Read text from images or scanned documents
string
Which pages to read (for documents with multiple pages). Examples:
1-5, 1,3,5, or all.Outputs
string
The extracted text content.
array
Array of page contents (for multi-page documents).
object
File metadata:
pageCount- Number of pagesfileType- Detected file typefileSize- Size in bytestitle- Document title (if available)author- Document author (if available)createdAt- Creation date (if available)
array
Extracted tables (when using structured mode).
boolean
Whether extraction completed successfully.
Related Nodes
Ask AI
Analyze and extract insights from parsed content.
Loop
Process multiple files or pages.